From General Assistant to Deterministic Reading Pipeline
Keep intelligence where it matters. Automate the rest.

In a recent post, I shared how a general-purpose personal AI assistant (OpenClaw) helped me finally establish a daily Classics reading habit that I had put off for years. That was a genuine breakthrough, because intelligence plus scheduled execution turned an intention into a routine that actually happened. LLM + cron = magic!
Once that routine was working consistently, however, a second question became unavoidable: which parts of this system still need intelligence, and which parts should simply run like clockwork? That question led me to a four-stage progression—discover, validate, harden, scale—that I now think applies well beyond this one project.
Today, general-purpose assistants are outstanding at discovery, design, and early iteration, but they are not always the best option for executing repetitive workflows. When a process is stable and predictable, keeping it in a general-purpose agent loop often means spending tokens on orchestration, possibly unnecessary rewrites of correct logic, and tolerating slow drift in formatting and behavior over time.
The Shift
So I rebuilt the same functionality as a hardened pipeline that runs on any commodity infrastructure, where the day-to-day execution is deterministic and the boundaries are explicit.
- Deterministic task: with the same inputs, the system follows the same sequence of steps every morning, so behavior is predictable rather than conversational.
- System-level cron: scheduling is owned by the operating system, which means timing is reliable and independent of context windows.
- Fixed email format: structure, MIME headers, and layout are generated from code without any LLM calls, so the output remains stable across months.
- No improvisation in execution: the plan is encoded in scripts and configuration, then repeated exactly until we intentionally change it.
Functionally, the output is the same: a daily reading email with verbatim book text, progress, and interpretation (see screenshot at the end). Operationally, it is entirely different, because there is no open-ended agent loop and no unnecessary reasoning in the components that should remain fixed.
What Stayed Intelligent vs. What Became Deterministic
This is the core design decision:
Keep intelligence for modern interpretation of old text.
Use deterministic software for everything
else.
In practice, this split becomes a clear contract between components:
crontab + run.shdefines the execution steps and enforces punctual execution—deterministic.read-book.pymanages state progression and chunk selection using deterministic logic with one call for modern interpretation (non-deterministic LLM call). The model is invoked only for interpretation, which is the only part of this workflow that genuinely benefits from model reasoning.send-daily.shdelivers the generated HTML through a stable email interface—deterministic.
Why This Matters
OpenClaw was exactly the right tool to dream, design, and bootstrap this use-case, because that stage depends on exploration and flexibility. Routine pipelines, by contrast, should not adapt unless you explicitly ask them to, and that is where deterministic software has a clear advantage of cost and focus.
Before hardening, I observed drift: minor email formatting variation and occasional behavioral changes that should have remained constant. I also kept getting rate limited by Claude, and API usage was becoming costly.
The hardened version solves all of the above problems by:
- Lower operating cost: token spend is concentrated on interpretation, which is where new value is produced, while scheduling, formatting, and delivery run as ordinary software.
- Higher reliability: fixed scripts and formats can be tested, diffed, and monitored.
- Cleaner ownership: system behavior lives in versioned code and configuration, so every change is explicit, reviewable, and easier to reason about over long periods.
From a productivity perspective, this distinction between dreaming and engineering matters. Prototyping speed helps in the moment, while engineering reliability is needed across every single day the system continues to run.
The Progression Pattern
I now think of this as a repeatable progression for AI-assisted productivity systems, especially when the goal is to move from experimentation to dependable operations. It starts with discovery, where you use a general assistant to explore alternatives and assemble a working first version quickly. Next comes validation, where you run the workflow in real conditions long enough to learn where variation adds value and where it introduces noise. Then you harden, moving repeatable behavior into deterministic scripts, schemas, and schedules so the system behaves consistently. Finally you scale, adding monitoring, ownership boundaries, and controlled change management so the workflow can expand without becoming fragile.
The reading pipeline is one instance of this pattern, but the same progression applies in many other settings:
- Daily research digests: source collection and ranking can be deterministic, while model usage is reserved for synthesis and interpretation.
- Sales follow-up: timing, sequencing, and templates can remain deterministic, while model personalization is applied selectively at the message layer.
- Internal reporting: data extraction and layout can be deterministic, while model reasoning is used where interpretation and narrative framing are genuinely needed.
Post-AI Software
A common claim is that AI means software as we know it is going away. I think the opposite is happening, and this project is a small but practical example of why.
Post-AI software is not less software; it is a clearer split of responsibilities between reasoning and reliability. Models handle judgment, interpretation, and ambiguity, while deterministic code handles schedules, state, formatting, and delivery. The strongest systems combine both layers. Agents are excellent at exploration and first drafts, while software remains essential for repeatability, cost control, auditability, and long-term maintainability.
Current Runtime
The system is now running on Linux as infrastructure, not as an ongoing conversation.
# Every morning at 11:07 UTC
7 11 * * * cd /home/sojoodi/reading-classics && ./run.shThat one line executes the same path each day, which means that if the scripts work today, they will continue to work tomorrow under the same inputs and assumptions.
Result
I still get the same daily reading experience I wanted from day one, but the operating model is far more stable: intelligence is used where it adds unique value, while execution, delivery, and formatting remain deterministic.
In practice, this is the pattern that compounds: use an intelligent assistant to design the machine, and then let well-structured software run that machine consistently over time.
Screenshot
An email like the one in the image below shows up in my inbox every morning.
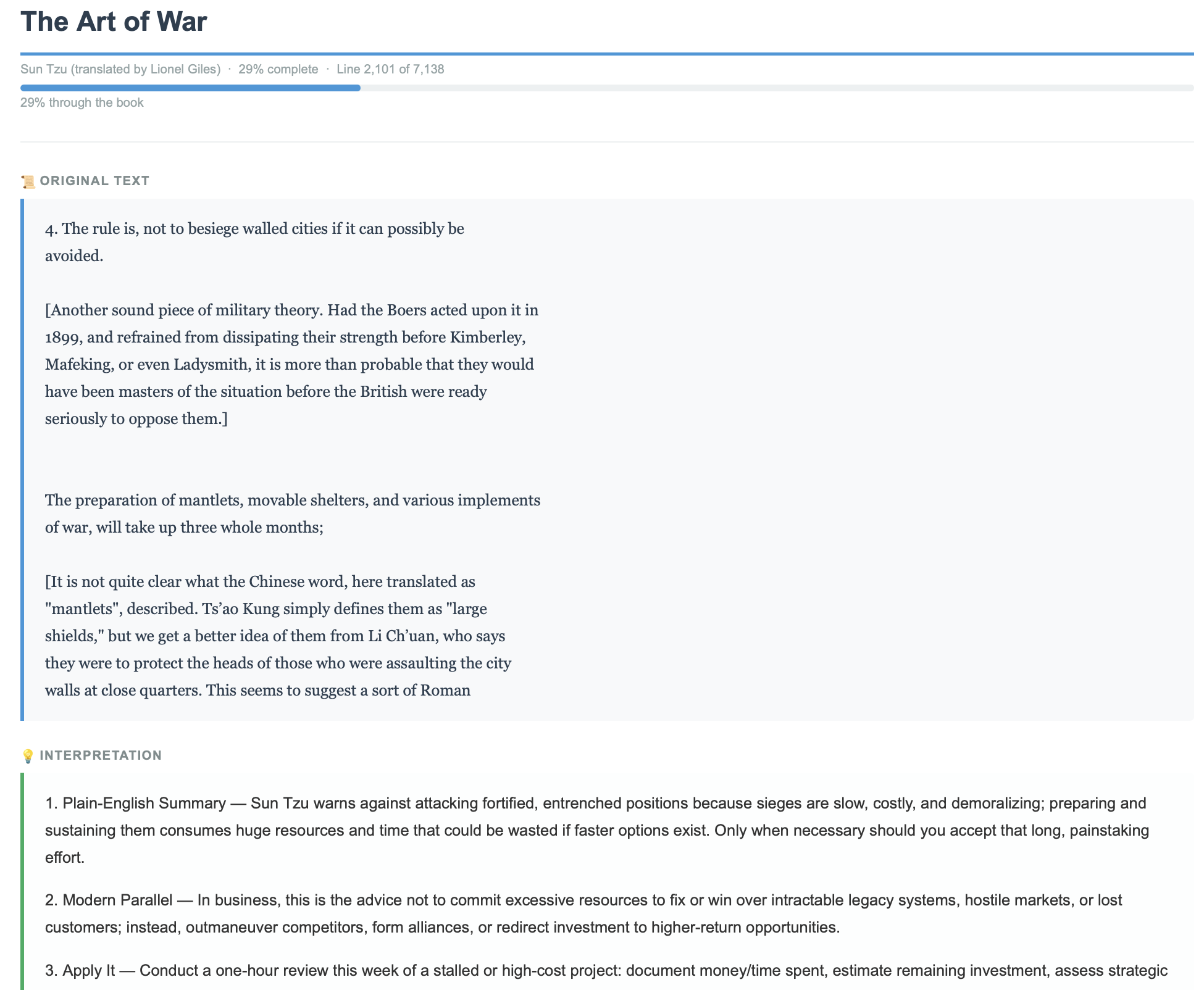
Daily deterministic output with a single intelligence layer for interpretation.
If you are building with agents, this pattern is worth remembering: agent-first to discover the workflow, deterministic-second to harden it.
Join me!
I hope you found this write-up useful. If you’d like, join me in reading the classics. I am one third through The Art of War. It will take a while, but next up will be Meditations by Marcus Aurelius.
— Sahand